Putting collation of text witnesses on a formal basis
Abstract of the paper
The paper presents an approach to the collation problem of text witnesses which is correct for all distance functions, whether or not they are a measure, and which is applicable to the alignment of any types of tokens, be it letters, words, or paragraphs. In contrast to existing approaches, we specify a formal model (in the form of an integer linear program (ILP)) that describes the optimization problem. For a special case that usually occurs in practice, we then transfer the ILP into a fast algorithm based on dynamic programming (DP) that optimally solves the alignment problem. In the second part of the paper, we apply our approach (named TSaligner) to the alignment of paragraphs of text witnesses –an alignment problem that has so far received little attention in the literature– and compare our results with those of CollateX.Details on the Experiments
We compared TSaligner with CollateX on different texts. CollateX provides two collation algorithms (and a third experimental one) to choose from, the Dekker-algorithm and the Needle-Wunsch-algorithm. Because CollateX's distance measures are designed for sentence word alignment rather than paragraph alignment, we have added two new distance measures to CollateX, the normalized Levenshtein distance and the Jaccard distance, which are more appropriate for paragraph alignment. We worked with the CollateX version dated June 18 2019 and added our custom distance measures –the latest official builds of CollateX could not be used because they threw different exceptions.
Distance measures
To find pairs of paragraphs that are similar and could be aligned, we need to define when paragraphs form a "good pair" or a "match". This is done by a so-called distance or similarity function. It takes two paragraphs and returns a result indicating how "good" a pair is. Often a threshold is defined and if the distance between the paragraphs is below or equal to the threshold they are considered to "match". Because finding a good measure for the distance of paragraphs is a task on its own, aligners normally provide a set of distance measures or allow to specify a custom distance measure. We choose to test with two distance measures:
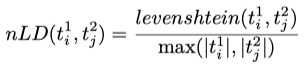
Another distance function we used is the Jaccard Distance (JD). Our experiments show that this distance measure leads to better results when aligning paragraphs than the (normalized) Levenshtein distance. It gives the ratio of the number of common words to the number of all words used in the two paragraphs, or rather 1 minus this ratio.
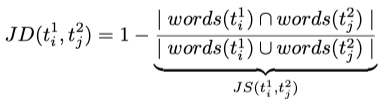
Application of the distance measures in CollateX and TSaligner
CollateX not directly works with distances but it only needs to know whether two paragraphs produce a match or not. Thus, we added a custom distance function for nLD and JD. They produce a match if and only if the calculated distance is below or equal to a given threshold c3. We tested with values 1.0 and 0.7 for c3.
TSaligner also uses the distance measures from above but in a slightly more mathematical way. Both distance functions, normalized Levenshtein distance and Jaccard distance, produce results in the interval [0, 1]. We subtract c3 from the distance. This will partially shift the interval into the negative range, e.g. for c3 = 0.7 to [-0.7, 0.3]. As not aligning two paragraphs adds a value of 0 to the total distance, we only align paragraphs with distances in the interval [-0.7, 0]. This way we ignore paragraph pairs with distance greater than c3. For two paragraphs that are aligned, however, their (now negative) distance is included in the costs.
Test data
We compared TSaligner with CollateX on two witnesses of each of the three texts, "Rumpelstilzchen" (in the following we abbreviate it by "Rumpel"), "Wally die Zweifelerin" ("Wally"), and "Aus der Knabenzeit" ("Knab").
| Text | Versions | # paragraphs | Length of paragraphs | Description |
|---|---|---|---|---|
| Rumpel | 18121857 | 3679 | short | German fairy tale. |
| Wally | 18521874 | 303300 | medium | Novel by the German novelist and dramatist Karl Ferdinand Gutzkow. |
| Knab | 18521873 | 197188 | long | Novel by Karl Ferdinand Gutzkow. |
The second column indicates the year of origin and the third column the number of paragraphs of the two respective witnesses. The fourth column gives our "rating" of the lengths of the paragraphs in the text witnesses.
Experimental Results
As the assessment of findings in the Humanities is often based on interpretation (cf. [23] in the paper) it is not possible to claim that one alignment is better than another. The assessment usually depends on the humanities question under study. With this in mind, we can only invite the reader to take a closer look at the alignments created by CollateX and TSaligner using the two distance functions, normalized Levenshtein distance and Jaccard distance. Here, we can only reflect our own observations. We believe that these are true for most applications.
When we look at the results of our experiments, TSaligner appears to produce alignments that are better, and by no means worse, than those generated by CollateX:
- Regarding the distance measures, Jaccard distance and normalized Levenshtein-distance don't give many differences when both text witnesses are very similar and TSaligner is used.
- CollateX with normalized Levenshtein distance produces comparably worse results than with Jaccard distance.
- When comparing TSaligner with Jaccard-distance and CollateX with Jaccard-distance, our approach appears to produce better result.
The following three subsections contain the alignments produced by the different approaches. For our internal evaluation the resulting alignments contain an additional column headed by "JS". It gives the Jaccard Similarities of the matched paragraphs which is given by 1 minus the Jaccard distance between the two paragraphs.
We marked the most interesting results for use with a
Alignments produced by TSaligner
| Text | nLD ( 1.0) | nLD ( 0.7) | JD ( 1.0) | JD ( 0.7) |
|---|---|---|---|---|
| Rumpel | Result | Result | Result | Result |
| Wally | Result | Result | Result | Result |
| Knab | Result | Result | Result | Result |
Alignments produced by CollateX (Dekker-algorithm)
| Text | nLD ( 1.0) | nLD ( 0.7) | JD ( 1.0) | JD ( 0.7) |
|---|---|---|---|---|
| Rumpel | Result | Result | Result | Result |
| Wally | Result | Result | Result | Result |
| Knab | Result | Result | Result | Result |
Alignments produced by CollateX (Needleman-Wunsch-algorithm)
| Text | nLD ( 1.0) | nLD ( 0.7) | JD ( 1.0) | JD ( 0.7) |
|---|---|---|---|---|
| Rumpel | Result | Result | Result | Result |
| Wally | Result | Result | Result | Result |
| Knab | Result | Result | Result | Result |
Details on the alignments produced by TSaligner
- Differences between the alignments of the two witnesses of Rumpel produced by TSaligner with nLD, c3=0.7 and JD, c3=1.0 can be found in rows (8 & 9), (23 & 24), (25 & 26), 30, (39 & 48), (44 & 49), (47 & 53), (80 & 84).
- For Wally, the results for JD with both c3 values are the same except for row 273.
- For Wally and nLD with both c3 values, the alignment is almost the same, differences are at rows (21 & 22), (104 &105), (165 &167), (201 & 204), and (267 & 271).
- For Knab and JD with both c3 values, the differences are in rows (3 & 4) ff, (5 & 8), 17 ff, (17 & 24), (19 & 26), (21 & 28), (23 & 30), (65 & 72).
- For Knab and nLD with both c3 values, the differences are the following: (3 & 4), 15 ff, (15 & 21) ff, (20 & 26) ff (26 & 32) ff, (100 & 107), (135 & 141) ff , (161 & 171) ff, (182 & 194) ff. Starting with the changes after row 100 they are very minor and are really just changed numbers.
Details on the alignments produced by CollateX (Dekker-algorithm)
- Wally with nLD, c3 = 0.7 and JD with c3 = 0.7 produces slightly different results, see rows 22, 76, 152, (208 & 211), and (286 & 290).
- Knab with nLD, c3 = 0.7 and JD with c3 = 0.7 produces very different results, see rows 19 ff, 33 ff, (43 & 42) ff, (57 & 54) ff, (60 & 54) ff, (113 & 108) ff, (134 & 128) ff, (162 & 153) ff, (171 & 161) ff, (178 & 167) ff, (186 & 174) ff, and (194 & 182) ff.
Discussion on the alignments of CollateX (Needleman-Wunsch-algorithm)
- Wally with nLD, c3 = 0.7 and JD with c3 = 0.7 produce the same alignment.
- Knab with nLD, c3 = 0.7 and JD with c3 = 0.7 produce almost the same alignment, differences can be found at rows 5, 19, 33, and 163.
- Some bad pairs for Rumpel and nLD, c3 = 0.7 are in rows 27, 29, 35, 55, 71 and 20 (the last one might be ok given the context).
- Some bad pairs for Rumpel and JD, c3 = 0.7 are in rows 6, 30, 31, 39 ff, 45, 52, 78.
Overall Observations
- Generally the alignments from CollateX with distance function JD with c3 = 1.0 and nLD with c3 = 1.0 are not really usable.
- When comparing the results for the Rumpel alignments with distance function JD we can see that CollateX misses many good paragraph pairs and also aligns many paragraphs that probably should not be aligned. The same is true for nLD and CollateX.
- For most humanities questions, TSaligner, compared to CollateX, produces the most useful results for Rumpel and better or equally good results for the other texts.
- In our opinion, the best alignments of the given texts are produced by TSaligner with JS with c3 = 0.7 for Knab and Wally. For Rumpel JD with c3 = 1.0 is better, due to the shorter sentences.
General shortcomings
There are two fundamental shortcomings that all paragraph aligners known to us - including ours - have. The first are short paragraphs with only a few words. They are more sensitive to changes and generally produce higher (in some sense worse) distances. The second shortcoming are paragraphs that either have a common initial part or similar endings with a paragraph of the other text variant. The problem is rooted in the segmentation of the text witnesses. For instance, if a paragraph C of the one text variant consists of the concatenation of two consecutive paragraphs A and B of the other text variant, then both possible alignments (C,A) and (C,B) are more or less worse. Because segmentation is treated as a separate step in the collation of text witnesses this cannot be fixed by the alignment step.
The two examples from the introduction of the paper
| Text | CollateX - Equality | CollateX - Levenshtein (max distance: 1) | CollateX - nLD ( 1.0) | TSaligner - nLD ( 1.0) |
|---|---|---|---|---|
| Example 1 | Result | Result | Result | Result |
| Example 2 | Result | Result | Result | Result |
To show some problems of CollateX with paragraphs, we constructed two synthetic examples in our paper. We let CollateX align the examples with the Dekker algorithm and the built-in distance function Levenshtein with distance parameter set to 1, nLD with c3 = 1 and the built-in equality function. For "equality" CollateX should treat two tokens (words or very short paragraphs in this case) as equal if they are the same text. For the built-in Levenshtein distance function, it should treat two tokens as equal if the Levenshtein distance is less than or equal to 1. For comparison we also did the alignment with TSaligner with nLD with c3 = 1.
Downloads
Contact
Martin Luther University Halle-Wittenberg | https://www.informatik.uni-halle.de/ti/mitarbeiter | https://www.informatik.uni-halle.de/ti/

